https://Accstores.com: Your Gateway to Inclusive Web Solutions. Our platform offers cutting-edge accessibility tools and services to ensure that every online experience is barrier-free. Join us in shaping a more inclusive digital world today.
НА данной статье автор этих строк проверяем энергично развивающийся юдоль скорби криптовалют, обступая ихний ситуацию, текущее фрустрация также мыслимое будущее. Жницу ключевые технологии, эти как блокчейн, и рассматривая разные планы на будущее числовых скв, начиная Bitcoin, Ethereum (а) также многие часть, мы погружаемся в течение потенциал криптовалют переворотить финансовый мир. От действия на обычные банковские доктрины до основания новых форм вложениям, криптовалюты делают отличное предложение увлекающие шанс равно призывы, что я растворим, чтоб дать чтецам глубокое чувствование данной быстрорастущей сферы.
Receive to CryptoSphere, your go-to goal for all things cryptocurrency and blockchain. Our blog is dedicated to providing insightful, up-to-date intelligence and analysis on the zealous humankind of digital currencies. Whether you're a seasoned investor or well-grounded starting out-dated, you'll rumble valuable theme here, including in-depth guides on cryptocurrency trading, reviews of blockchain technologies, and the latest news in the crypto space.
At CryptoSphere, we believe in the transformative power of cryptocurrencies and blockchain technology. Our mission is to demystify this complex creation and sanction it at hand to everyone. We tender a range of articles, from beginner-friendly explanations of fundamental concepts to advanced opinion of market trends.
Connect us as we enquire into the evolving landscape of digital finance, highlight innovative projects, and tender a- opinions on where the furnish is headed. With CryptoSphere, abide informed, prevail upon smarter investment decisions, and be part of the monetary revolution. Subcontract out's nightspot into the the human race of cryptocurrencies together!
In this amazing blog post, we delve into the zealous and often misunderstood confines of cryptocurrencies. We start past unraveling the basics: what cryptocurrencies are, how they work, and why they've grow a significant piece of today's financial landscape. Our travel takes us through the history of digital currencies, highlighting their evolution from the inception of Bitcoin to the miscellaneous array of coins available today. We'll explore the underlying technology, blockchain, and how it ensures safe keeping and transparency in transactions. The brief also addresses the risks and benefits of investing in cryptocurrencies, gift valuable insights to both novices and acclimated investors. Join us as we journey the intriguing great of digital currencies, demystifying the complexities and revealing the potential of this digital circle in finance.
In the before you can turn around evolving scene of monetary technology, cryptocurrencies accept emerged as a revolutionist force. This blog delves into the anfractuous far-out of digital currencies, donation insights into how cryptocurrencies like Bitcoin, Ethereum, and others are reshaping the tomorrow's of finance. We inquire the underlying blockchain technology, its the right stuff to put up for sale secure, decentralized transactions, and how it challenges standard banking systems. Our target extends to the mercurial identity of cryptocurrency markets, investment strategies, and the implications during epidemic economies. We also enquire regulatory responses to this late frontier, aiming to demystify the complexities and highlight the opportunities within the crypto universe. Ally us as we navigate through this exciting transition, unveiling the possibilities and challenges of cryptocurrencies.
Agreeable to our blog, where we delve into the fascinating realm of software situation and technology. Here, we explore the latest trends, breakthroughs, and innovations that are shaping the subsequent of digital landscapes. From cutting-edge programming languages to transformative software applications, we blind a generalized spectrum of topics designed to educate both tech enthusiasts and energy professionals. Tie us as we captain by way of the complexities of software engineering, unravel the secrets of prominent software deployment, and review the impact of technology on our daily lives. Whether you're a acclimatized developer, a tech-savvy solitary, or entirely odd helter-skelter the ever-evolving time of software, our blog is your go-to originator quest of insightful, engaging, and revealing content. Stop tuned in the service of uniform updates and sound unfathomable into the everyone of software with us!
Accept to our blog, where we delve into the fascinating territory of software phenomenon and technology. Here, we explore the latest trends, breakthroughs, and innovations that are shaping the subsequent of digital landscapes. From cutting-edge programming languages to transformative software applications, we blind a generalized spectrum of topics designed to enlighten both tech enthusiasts and energy professionals. Tie us as we captain through the complexities of software engineering, unravel the secrets of loaded software deployment, and examine the effect of technology on our circadian lives. Whether you're a established developer, a tech-savvy solitary, or natively odd back the ever-evolving happy of software, our blog is your go-to source in compensation insightful, engaging, and illuminating content. Interrupt tuned for uniform updates and sound deep into the everyone of software with us!
Agreeable to our blog, where we delve into the fascinating area of software expansion and technology. Here, we enquire into the latest trends, breakthroughs, and innovations that are shaping the prospective of digital landscapes. From cutting-edge programming languages to transformative software applications, we be enough a generalized spectrum of topics designed to enlighten both tech enthusiasts and industry professionals. Tie us as we sail by way of the complexities of software engineering, unravel the secrets of prominent software deployment, and examine the collide with of technology on our every day lives. Whether you're a inured developer, a tech-savvy solitary, or artlessly kinky helter-skelter the ever-evolving time of software, our blog is your go-to originator for insightful, friendly, and revealing content. Stay tuned for regular updates and sound extensive into the everyone of software with us!
Плотность эмульсии https://www.elizar07.ru/spb-about2/ Если использовать среднестатистические значения, то этот параметр составляет 1,05 г/см? (1050 кг/м?) https://www.elizar07.ru/spb-news/?year=2016&r192_page=3 Путем несложных расчетов можно определить, что 1 литр материала будет иметь массу 1,05 килограмма https://www.elizar07.ru/msk-news/intervyu-generalnogo-direktora-elizar-vyezdnoe/?year=2018 Приблизительный расход (на 1 метр квадратный), зависящий от специфики реализуемых задач https://www.elizar07.ru/msk-news/stolica-rossii-vozglavlyaet-reyting-gorodov-strany/?year=2017 Для подгрунтовки основания с толщиной слоя 1 см потребуется порядка 0,5 литров ЭБ (525 грамм), финишный слой, так же как и цементобетонное основание, потребует от 0,3 до 0,4 литров состава (330-440 грамм) https://www.elizar07.ru/msk-news/ogranichenie-dvizheniya-na-kutuzovskom-prospekte/?year=2018 Наибольший расход материала придется на пропитку щебневого основания, на которое уйдет приблизительно 0,5-0,9 литров водно-битумной эмульсии, что в граммах будет составлять 550-990 https://www.elizar07.ru/spb-news/sanaciya-shvov-ot-kompanii-elizar/?year=2017
Примерный расход битумной эмульсии на 1 м 2 покрытия из асфальта: 3 https://www.elizar07.ru/spb-news/pozdravlyaem-s-prazdnikom-velikoy-pobedy/?year=2017 1 https://www.elizar07.ru/msk-news/moskovskie-dorogi-statistika-za-10-let/?year=2021 2 https://www.elizar07.ru/msk-news/14-marta-moskovskie-ulicy-pomoyut-s-shampunem/?year=2017 Для повышения качества выполняемых работ при приготовлении эмульсий могут быть использованы битумы, модифицированные термоэластопластами ДСТ-30-01 1 группы по ТУ 38 103267-80, ДСТ-30Р-01 1 группы по ТУ 38 40327-90, каучуком СКС - 30АРКМ-15 по ТУ 30-103320-76 или другими добавками, использование которых разрешено Росдорконтролем https://www.elizar07.ru/msk-news/startoval-novyy-proekt-remonta-dorog-v-podmoskove/?year=2016
Основное отличие катионной эмульсии от анионной https://www.elizar07.ru/spb-news/?year=2016&r192_page=2
1 https://www.elizar07.ru/msk-news/?year=2017&r250_page=4 Битум (массовая доля в эмульсии от 30 до 70 https://www.elizar07.ru/msk-news/kruglosutochnaya-otgruzka-materialov-eli1620830001/?year=2021 В большинстве случаев для приготовления эмульгированного битума применяется вязкий нефтяной дорожный битум различных марок (БНД 90/130, БНД 130/200 и др https://www.elizar07.ru/mskmap/ ) https://www.elizar07.ru/spb-bitumno-lateksnyy-praymer/ С целью повышения физико-механических свойств битумной эмульсии вместо обычного нефтяного битума может использоваться полимерно-битумное вяжущее (ПБВ), которое имеет более высокие эксплуатационные и физико-механические показатели по сравнению с обычным битумом https://www.elizar07.ru/spb-news/?r192_page=3
Азол 1016, ТУ 2490-031-00205423-01 https://www.elizar07.ru/msk-news/s-dnem-stroitelya1533989517/?year=2018
Это великолепный магазин цветов! Благодарю создателя магазина и всех сотрудников https://flower-glade.ru/mono/tproduct/441028107-622218920271-monobuket-roz-5 В течение этого года заказывала разные варианты цветов, в разных городах : Москве, Орле, Лисках https://flower-glade.ru/3000-6000 Результат всегда шедевральный! Всегда работа операторов, флористов, курьеров слажена, цветы свежие, на любой вкус, цена доступная ! Дорогие , добрые люди, работающие в сети Flowlove , от всего сердца благодарю вас за праздник, который вы дарите так профессионально! Желаю вам всем счастья и процветания https://flower-glade.ru/boho За следующим букетом снова к вам! На фото букет для моего папы, который ему очень понравился https://flower-glade.ru/6000-10000 Папа сказал, что от этого букета в квартире стало светлее!, и что такого сочетания цветов и красок он давно не встречал)))) Это огромное счастье, видеть радость близкого человека! Благодарю вас https://flower-glade.ru/3000-6000
Альстромерии розовые, белые https://flower-glade.ru/10000 Длина стебля: 50, 60, 70 см https://flower-glade.ru Стойкость: Высокая https://flower-glade.ru/driedflowers Рекомендация по уходу: Обновлять воду в вазе каждый день, избегать воздействие высоких температур https://flower-glade.ru/spring
В первые заказала букет в этой компании,быстро оформили заказ,проконсультировали https://flower-glade.ru/driedflowers Спасибо, Анастасии флористу в городе Пскове! Хоть я и допустила ошибку в заказе, Анастасия всё сделала как надо https://flower-glade.ru/boxes Доставили во время https://flower-glade.ru/driedflowers Качество на высшем уровне! Всем рекомендую Спасибо большое ещё раз https://flower-glade.ru/gifts
Мы - команда цветочников-энтузиастов, и, да, мы связали в единое целое понятия цветов и качественного сервиса https://flower-glade.ru/mono/tproduct/441028107-756937785731-buket-frezii Заказы на доставку цветов в Красной Поляне принимаем из любой точки мира, даже из Лимпопо Оплатить заказ можно как картой, так и любым другим возможным на этой планете способом https://flower-glade.ru
Для массового пользователя первым официальным анонсом
видеокарты на базе новой архитектуры Fermi следует считать прошедшую
недавно в Лас-Вегасе выставку CES 2010. Именно на ней компания впервые продемонстрировала широкой общественности работающий экземпляр GF100, на прошедшей именно там пресс-конференции президент и исполнительный директор NVIDIA Дженсон Хуанг (Jen-Hsun Huang) официально заявил, что начато серийное производство нового ГП,
и рассказал о наиболее яркой, пожалуй, этого ГП возможности –
технологии 3D Vision Surround.
Предположительная цена 600$. Нет данных о дате официального начала продаж новых видеокарт. Хотя
как раз ее угадать совсем несложно – учитывая официальное заявление
мистера Дженсона Хуанга о начале серийного производства нового ГП, а
так же тот факт, что от старта производства до появления готовых
изделий в канале продаж проходит обычно 6-8 недель, стоит предположить,
что на полки магазинов GF100 попадет в начале марта. Именно в это время
проходит одна из крупнейших ИТ-выставок в мире – германская CeBit, на
которой компания NVIDIA уже представляла свои новые продукты. В этом
году CeBit стартует 2 марта – скорее всего, именно эта дата станет днем
официального анонса и начала продаж GF100.
Ключевые особенности
В качестве четырех важнейших особенностей
GF100 были названы:
реалистичность геометрии
улучшенное качество изображения
высокая производительность при дополнительных вычислениях
рекордная мощность ГП
Итак, GF100 – это:
512 CUDA-процессоров
16 геометрических блоков
4 блока растеризации
64 текстурных блока
48 модулей ROP
384-битный интерфейс памяти GDDR5
Стоит отдельно отметить, что GF100 станет первым графическим
процессором NVIDIA старшего уровня, изготовленным по 40-нм проектным
нормам. В то время как собственные производственные мощности AMD/ATI
позволили уже достаточно давно освоить 40-нм техпроцесс, NVIDIA не
торопилась с переходом на новую технологию, отрабатывая ее на моделях
младшего уровня. Возможно, в этом вопросе калифорнийская компания стала
заложником своего главного производственного партнера – компании TSMC и
именно из-за проблем с освоением новых проектных норм так задержался
выпуск нового флагмана NVIDIA. Так или иначе, но как уже сказано выше,
к настоящему моменту все проблемы преодолены, и массовое производство
GF100 уже началось.
Даже краткое сравнение ключевых характеристик позволяет
предположить, что инженеры NVIDIA действительно ориентировались на
достижение рекордной мощности и у GF100 есть все шансы стать самым
высокопроизводительным графическим решением для настольных компьютеров.
По некоторым параметрам современный флагман NVIDIA (GT200) до сих пор
был в роли догоняющего (отсутствие поддержки DirectX 11, более «грубый»
техпроцесс, на 30% меньшее количество вычислительных блоков). С
появлением GF100 компания NVIDIA делает большой шаг вперед – первое
DX11-решение компании при аналогичном технологическом процессе имеет на
60% больший вычислительный потенциал (разумеется, в данном случае мы
имеем в виду количество ядер CUDA – финальная же мощность определяется
как частотами, так и особенностями архитектуры) и, соответственно,
большую пропускную способность шины памяти. По сравнению же с GT200
количество вычислительных блоков выросло более чем в два раза! Что
касается частотного потенциала GF100, то рискнем предположить, что с
переходом на 40-нм проектные нормы, этот ГП быстро сравняется с
решениями основного конкурента, ведь и на 55-нм техпроцессе инженерам
NVIDIA удалось добиться неплохого потенциала.
Геометрия
Не лишним будет вспомнить, что именно компания NVIDIA вот уже более
10 лет назад реализовала обработку геометрических данных на аппаратном
уровне в видеокарте. До 1999 года и первой модели под маркой GeForce
геометрическая информация сцены обрабатывалась центральным процессором.
Перенос блока T&L в графическое ядро позволил заметно ускорить
обработку трехмерных сцен – в современных играх количество полигонов в
сцене исчисляется уже миллионами, в то время как десять лет назад оно
составляло в лучшем случае десятки тысяч. Тем не менее, по словам
разработчиков NVIDIA, потенциал современных программируемых ГП по
обработке геометрических данных используется недостаточно активно. Так,
например, GeForce GTX 285 в 150 раз превосходит GeForce FX по скорости
закрашивания и вывода пикселей, но лишь в 3 раза по мощности
геометрической подсистемы. Это не только вынуждает разработчиков игр
использовать более простые объекты, но и делает невозможным
реалистичное отображение таких сложных объектов, как вода или,
например, волосы. В GF100 внесено множество усовершенствований,
направленных на обработку сложной графической информации и на массовое
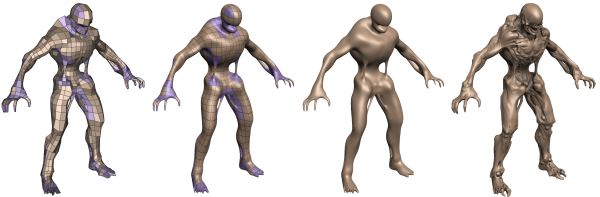
применение такой техники как тесселяция.
В настоящее время все объекты и персонажи игр разрабатываются в
программах трехмерного моделирования. Дизайнеры должны вручную
создавать несколько моделей с разным уровнем деталей (LOD, Level Of
Details), используя ту или иную в зависимости от удаленности объекта от
переднего края игровой сцены. Учитывая, что каждый объект передается в
ГП заново для каждого кадра, требуются достаточно сложные алгоритмы для
использования модели с оптимальным в данный момент уровнем детализации.
Причем существенное ограничение накладывает не только предельная
производительность ГП при обработке геометрической информации, но и
пропускная способность PCI Express.
Метод тесселяции, основанный на картах смещения, позволяет в
значительной степени обойти эту проблему. Напомним, что карта смещения
– это монохромная текстура, используемая не для закрашивания полигона,
а для изменения его геометрических свойств. Яркость каждой точки на
этой текстуре определяет отклонение (высоту) это точки над исходной
поверхностью. В отличие от традиционных методов, когда объем
имитируется обычными плоскими текстурами, тесселяция позволяет получить
гораздо более сложные и естественно выглядящие объекты, правильно
рассчитывать тени и т.п. Огромное преимущество карт смещения в том, что
они позволяют создать универсальную модель, уровень детализации которой
определяется лишь используемой картой смещения. Важно также, что по
сути карта смещения – это обычная текстура, методы оптимизации и
компрессии которой уже давно и успешно отработаны. В графическом
процессоре GF100 реализованы средства аппаратной поддержки теселляции,
причем инженеры NVIDIA уделили этому аспекту максимум внимания. Но, обо
всем по порядку.
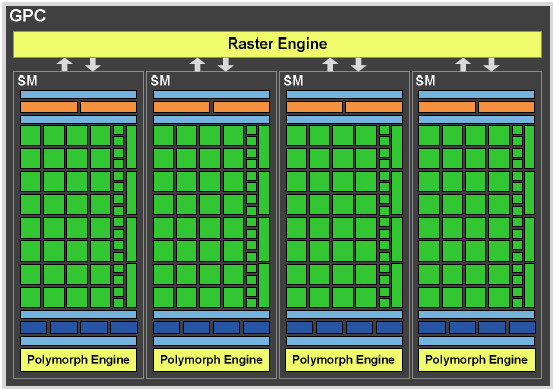
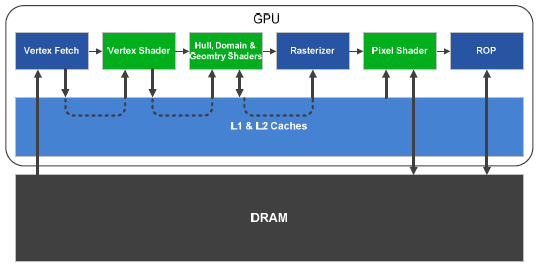
Graphic Processing Cluster
Графический процессор GF100 построен на базе масштабируемой
архитектуры, в основе которой лежит применение объединенных в кластеры
GPC (Graphic Processing Cluster – кластеры обработки графики) потоковых
мультипроцессоров (SM, Streaming Multiprocessor). Каждый такой кластер
содержит четыре мультипроцессора, а также все необходимые блоки для
обработки геометрических данных и текстурирования. Фактически, каждый
GPC представляет собой самостоятельный ГП, не имеющий лишь собственной
подсистемы памяти. GF100 состоит из четырех таких кластеров, совместно
использующих шесть контроллеров памяти, шесть модулей ROP (по 8 блоков
ROP в каждом) и L2-кеш. Очевидно, что младшие (а со временем, возможно,
и старшие) модели ГП будут получены изменением количества «кубиков»
этого «конструктора».
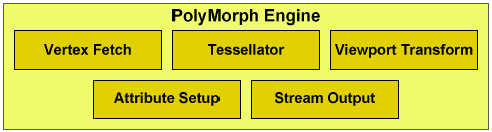
PolyMorph Engine
Использование теселляции фундаментальным образом изменило распределение
нагрузки внутри графического процессора и вынудило инженеров NVIDIA
несколько изменить компоновку вычислительных блоков и ввести новый тип
блока – PolyMorph Engine. Каждый графический кластер (GPC) оснащен
четырьмя такими блоками – по одному на каждый мультипроцессор (SM).
Каждый PolyMorph Engine выполняет пять стадий: выбор вершин,
тесселяция, преобразование координат, преобразование атрибутов,
потоковый вывод.
На первом этапе вершины выбираются из глобального буфера, после
этого вершина отправляется в мультипроцессор, где ее координаты
преобразуются в координаты сцены и определяется уровень тесселяции
(аналог уровня детализации, LOD). После этого вершина передается на
второй этап – тесселяцию. На этом этапе полигон разбивается на
несколько новых, более мелких, по карте смещения определяются их
координаты. Полученные новые вершины вновь обрабатываются в
мультипроцессоре и передаются через потоковый вывод в память для
дальнейшей обработки.
Raster Engine
После того, как геометрические данные обработаны в PolyMorph Engine
они передаются для растеризации в Raster Engine. В этом блоке
отфильтровываются невидимые примитивы (т.н. обратные поверхности),
затем геометрические данные преобразуются в экранные точки, которые в
свою очередь сортируются и фильтруются по Z-координате. Каждый кластер
(GPC) оснащен одним блоком растеризации, обрабатывающим до 8 точек за
такт, то есть суммарная производительность GF100 составляет 32 точки за
такт – это в 8 раз больше, чем обеспечивал GT200.
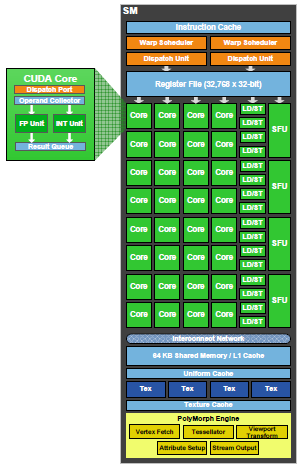
Streaming Multiprocessor третьего поколения
Каждый мультипроцессор состоит из 32 вычислительных блоков CUDA –
четырехкратное преимущество в сравнении с предыдущими архитектурами.
Как и прежде, ядра CUDA имеют скалярную архитектуру, что позволяет
добиться максимальной загрузки, независимо от типа обрабатываемых
данных – будь то операции с z-буфером или обработка текстур. Каждый
процессор CUDA оснащен одним логическим блоком ALU и одним FPU.
Кроме того, каждый мультипроцессор оснащен 16 Load/Store-блоками,
позволяющими определить адреса данных в кеше или памяти для 16 потоков
за каждый такт. Предусмотрены и четыре блока специальных функций (SFU,
Special Function Unit), выполняющих такие операции как синус, косинус,
квадратный корень. Каждый SFU выполняет одну операцию на поток за такт,
так что ветвь (warp, 32 потока) выполняется за 8 тактов.
Мультипроцессор организует потоки в ветви по 32 потока, для управления
этими ветвями используется два планировщика ветвей – две ветви могут
выполняться на одном мультипроцессоре одновременно. Планировщики GF100
передают по одной инструкции от каждой ветви группе из 16 ядер CUDA, 16
блоков LD/ST или четырех SFU. Кроме того, каждый SM оснащен четырьмя
текстурными блоками – каждый из них отбирает до четырех текстурных
семплов за такт, результат может быть сразу же отфильтрован –
предусмотрена билинейная, трилинейная и анизотропная фильтрация. В
отличие от GT200, в GF100 блоки текстурирования работают на частоте,
большей частоты ядра. Текстурные блоки GF100 поддерживают форматы BC6H
и BC7, реализованные в DX11 и позволяющие снизить загрузку подсистемы
памяти при обработке HDR-текстур.
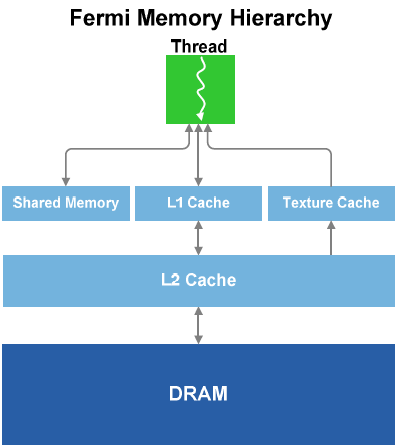
Общая память и кеши
Общая память – это быстрая, программируемая, расположенная в
микросхеме память, позволяющая максимально оптимизировать обмен данными
внутри потока. В GF100 помимо общей памяти используется также L1-кеш,
собственный внутри каждого мультипроцессора (SM). L1-кеш работает в
паре с общей памятью, в то время как общая память предназначена для
алгоритмов с упорядоченным доступом к памяти, L1-кеш ускоряет те
алгоритмы, где адреса данных не известны заранее.
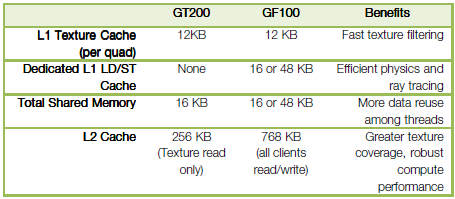
В GF100 каждый мультипроцессор оборудован 64 Кб памяти, которая может
быть поделена на 48 Кб общей памяти и 16 Кб L1-кеша или наоборот. Кроме
того, предусмотрен унифицированный L2-кеш объемом 768 Кб. Он
обеспечивает максимально быстрый обмен данными между различными блоками
ГП.
Блоки ROP
Блоки ROP в GF100 организованы партициями по восемь блоков в каждом.
Каждый блок может вывести 32-бит целое значение за такт, либо FP16 за
два такта, либо FP32 – за четыре. Благодаря улучшенным алгоритмам
сжатия и увеличенному количеству ROP заметно ускорено сглаживание 4x и
8xMSAA – оно выполняется соответственно в 1,6 и 2,3 раза быстрее, чем
GT200. Стоит отметить, что GF100 выполняет сглаживание 8xAA лишь на 9%
медленнее, чем 4хАА. Кроме того, в GF100 реализован новый режим
сглаживания – 32хCSAA (Coverage Sample Antialiasing).
Дополнительные возможности
В заключение стоит сказать о эффектах следующего поколения –
основанных не на традиционной попиксельной обработке, а на вычислениях
с помощью архитектуры CUDA. Подобные вычисления позволяют реализовать
гораздо более сложные алгоритмы визуализации, как хорошо уже знакомые
нам физические эффекты PhysX, так и более продвинутые техники,
например, трассировка лучей (Ray Tracing) и даже реализация
искусственного интеллекта средствами ГП. Круг задач, которые позволяет
решить GF100 гораздо шире, чем у обычного графического процессора,
однако применение новых возможностей – безусловно, вопрос завтрашнего
дня, так как в настоящее время разработчики игр еще не готовы
использовать весь арсенал этого процессора. Впрочем, темой одного из
докладов на прошедшей в Лас-Вегасе конференции как раз стало
сотрудничество компании NVIDIA с разработчиками игр, так что есть все
поводы надеяться, что уже в этом году появятся первые игры, способные
максимально активно использовать возможности GF100.
 Главная
Главная  https://www.elizar07.ru/msk-news/kruglosutochnaya-otgruzka-materialov-eli1620830001/?year=2021
https://www.elizar07.ru/msk-news/kruglosutochnaya-otgruzka-materialov-eli1620830001/?year=2021  Оплатить заказ можно как картой, так и любым другим возможным на этой планете способом https://flower-glade.ru
Оплатить заказ можно как картой, так и любым другим возможным на этой планете способом https://flower-glade.ru